此文章基於前篇 [最佳控制] 線性系統的最佳參數估計 - Kalman Filter (0);強烈建議讀者先參閱前篇再行閱讀此文。此文將利用 計算 probability density 方式來求解 Kalman filter。
考慮離散時間動態系統
\[
x(k+1) = Ax(k) + w(k);\;\; y(k) = Cx(k) + v(k)
\]且 $w \sim N(0,Q)$ 為製程雜訊 process noise 或稱 干擾 process disturbance;$v \sim N(0,R)$ 為量測雜訊 (measurement noise) ; $x(0) \sim N(\bar x(0), Q(0))$;$x \in \mathbb{R}^n, A \in \mathbb{R}^{n \times n}, C \in \mathbb{R}^{p \times n}, y \in \mathbb{R}^p$,Kalman filter 便是在試圖回答:假設狀態未知我們只能拿到量測輸出,則最佳的狀態估計該是如何?
First Step : $k=0$
假設 初始狀態 $x(0)$ 為 mean $\bar x(0)$ 且 convariance matrix $Q(0)$ 的 normal distrbuted 隨機向量,亦即
\[
x(0) \sim N(\bar x(0), Q(0))
\]接著獲得 初始 (受雜訊污染的) 量測輸出 $y(0)$ 滿足下式
\[
y(0) = C x(0) + v(0)
\]其中 $v(0) \sim N(0, R)$ 為 雜訊 (measurement noise)。
我們的目標:獲得 conditional density $p_{x(0)|y(0)}(x(0) | y(0))$ ,則我們的狀態估計 $\hat x$ 即可透過此 conditional density 求得
$$\hat x := \arg \max_x p_{x(0)|y(0)}(x(0) | y(0))$$
Comments:
1. 若未知 $\bar x(0)$ 或者 $Q(0)$ 則我們通常選 $\bar x(0) :=0$ 且 $Q(0)$ 很大 來表示我們對初始狀態所知甚少 (noninformative prior)。
2. 若量測過程中受到大的雜訊,則我們會給予較大的 $R$。若量測過程十分精確沒有太多雜訊汙染我們的輸出 $y$ 則 $R$ 較小。
3. Conditional density 描述了在我們獲得 初始量測輸出 $y(0)$ 之後我們對於 $x(0)$ 的了解。
現在回歸我們的目標,究竟該如何推得 $p_{x(0)|y(0)}(x(0) | y(0))$ ?
首先考慮 $(x(0), y(0))$ 如下
\[\left[ {\begin{array}{*{20}{c}}
{x\left( 0 \right)}\\
{y\left( 0 \right)}
\end{array}} \right] = \left[ {\begin{array}{*{20}{c}}
I&0\\
C&I
\end{array}} \right]\left[ {\begin{array}{*{20}{c}}
{x\left( 0 \right)}\\
{v\left( 0 \right)}
\end{array}} \right]
\]假設 $v(0)$ 與 $x(0)$ 彼此互為獨立。注意到 $x(0), v(0)$ 為 joint normal 亦即
\[\left[ {\begin{array}{*{20}{c}}
{x\left( 0 \right)}\\
{v\left( 0 \right)}
\end{array}} \right] \sim N\left( {\left[ {\begin{array}{*{20}{c}}
{\bar x\left( 0 \right)}\\
0
\end{array}} \right],\left[ {\begin{array}{*{20}{c}}
{Q\left( 0 \right)}&0\\
0&{{R}}
\end{array}} \right]} \right)\]
上述 $[x(0) \;\; y(0)]$ 為 $[x(0) \;\; v(0)]$ 線性轉換 且 故我們可以馬上知道
\[\begin{array}{l}
\left[ {\begin{array}{*{20}{c}}
{x\left( 0 \right)}\\
{y\left( 0 \right)}
\end{array}} \right]\sim N\left( {\left[ {\begin{array}{*{20}{c}}
I&0\\
C&I
\end{array}} \right]\left[ {\begin{array}{*{20}{c}}
{\bar x\left( 0 \right)}\\
0
\end{array}} \right],\left[ {\begin{array}{*{20}{c}}
I&0\\
C&I
\end{array}} \right]\left[ {\begin{array}{*{20}{c}}
{Q\left( 0 \right)}&0\\
0&R
\end{array}} \right]{{\left[ {\begin{array}{*{20}{c}}
I&0\\
C&I
\end{array}} \right]}^T}} \right)\\
\Rightarrow \left[ {\begin{array}{*{20}{c}}
{x\left( 0 \right)}\\
{y\left( 0 \right)}
\end{array}} \right] \sim N\left( {\left[ {\begin{array}{*{20}{c}}
{\bar x\left( 0 \right)}\\
{C\bar x\left( 0 \right)}
\end{array}} \right],\left[ {\begin{array}{*{20}{c}}
I&0\\
C&I
\end{array}} \right]\left[ {\begin{array}{*{20}{c}}
{Q\left( 0 \right)}&0\\
0&R
\end{array}} \right]\left[ {\begin{array}{*{20}{c}}
I&{{C^T}}\\
0&I
\end{array}} \right]} \right)\\
\Rightarrow \left[ {\begin{array}{*{20}{c}}
{x\left( 0 \right)}\\
{y\left( 0 \right)}
\end{array}} \right]\sim N\left( {\left[ {\begin{array}{*{20}{c}}
{\bar x\left( 0 \right)}\\
{C\bar x\left( 0 \right)}
\end{array}} \right],\left[ {\begin{array}{*{20}{c}}
{Q\left( 0 \right)}&{Q\left( 0 \right){C^T}}\\
{CQ\left( 0 \right)}&{CQ\left( 0 \right){C^T} + R}
\end{array}} \right]} \right)
\end{array}\]現在有了 $x(0), y(0)$ 的 joint density, 注意到此 joint density 為 normal,故若要計算 conditonal density of $x(0)$ given $y(0)$,亦即 $p_{x(0)|y(0)}(x(0)|y(0))$ ;則我們可以使用前述文章討論的 FACT 3 來求得,亦即
\[
p_{x(0)|y(0)}(x(0)|y(0)) = n(x(0), m, P)
\]其中
\[\left\{ {\begin{array}{*{20}{l}}
\begin{array}{l}
m = \bar x\left( 0 \right) + L\left( 0 \right)(y\left( 0 \right) - C\bar x\left( 0 \right))\\
L\left( 0 \right): = Q\left( 0 \right){C^T}\left( {CQ\left( 0 \right){C^T} + R} \right)_{}^{ - 1}
\end{array}\\
{P = Q\left( 0 \right) - Q\left( 0 \right){C^T}\left( {CQ\left( 0 \right){C^T} + R} \right)_{}^{ - 1}CQ\left( 0 \right)}
\end{array}} \right.\]則 optimal state estimation $\hat x$ 及為 具有最大 conditional density 的 $x(0)$;對於 normal distribution 而言,此 $\hat x$ 剛好為 mean;故我們選 $\hat x(0) := m$;且上式中 $P := P(0)$ 表示獲得 量測輸出 $y(0)$ 之後的 variance
Next Step: State Prediction
考慮現在狀態從 $k=0$ 移動到 $k=1$,我們有
\[
x(1) = Ax(0) + w(0)
\]亦可將其寫成線性轉換型式:
\[x\left( 1 \right) = \left[ {\begin{array}{*{20}{c}}
A&I
\end{array}} \right]\left[ {\begin{array}{*{20}{c}}
{x\left( 0 \right)}\\
{w\left( 0 \right)}
\end{array}} \right]\]其中 $w(0) \sim N(0, Q)$ 為 系統干擾 (disturbance) 或稱 製程雜訊 (process noise)。若 狀態受到大的外部擾動,則可以想見 會有較大的 $Q$ convaraince matrix。同理若外部干擾較小則有較小的雜訊。
故我們目標:要計算 conditional density $p_{x(1)|y(0)}(x(1),y(0))$
現在我們需要 conditional on joint density $(x(0),w(0))$ given $y(0)$,假設 $w(0)$ 與 $x(0),v(0)$ 彼此互為獨立,則我們可寫
\[\left( {\left[ {\begin{array}{*{20}{c}}
{x\left( 0 \right)}\\
{w\left( 0 \right)}
\end{array}} \right]|y\left( 0 \right)} \right)\sim N\left( {\left[ {\begin{array}{*{20}{c}}
{\hat x\left( 0 \right)}\\
0
\end{array}} \right],\left[ {\begin{array}{*{20}{c}}
{P\left( 0 \right)}&0\\
0&Q
\end{array}} \right]} \right)\]故現在利用 前述文章討論的 FACT 3' 來求得 conditional density,亦即
\[\begin{array}{l}
\left( {\left[ {\begin{array}{*{20}{c}}
{x\left( 0 \right)}\\
{w\left( 0 \right)}
\end{array}} \right]|y\left( 0 \right)} \right)\sim N\left( {\left[ {\begin{array}{*{20}{c}}
{\hat x\left( 0 \right)}\\
0
\end{array}} \right],\left[ {\begin{array}{*{20}{c}}
{P\left( 0 \right)}&0\\
0&Q
\end{array}} \right]} \right)\\
\Rightarrow \left( {x\left( 1 \right)|y\left( 0 \right)} \right)\sim N\left( {\left[ {\begin{array}{*{20}{c}}
A&I
\end{array}} \right]\left[ {\begin{array}{*{20}{c}}
{\hat x\left( 0 \right)}\\
0
\end{array}} \right],\left[ {\begin{array}{*{20}{c}}
A&I
\end{array}} \right]\left[ {\begin{array}{*{20}{c}}
{P\left( 0 \right)}&0\\
0&Q
\end{array}} \right]{{\left[ {\begin{array}{*{20}{c}}
A&I
\end{array}} \right]}^T}} \right)\\
\Rightarrow \left( {x\left( 1 \right)|y\left( 0 \right)} \right)\sim N\left( {A\hat x\left( 0 \right),AP\left( 0 \right){A^T} + Q} \right)
\end{array}\]故 conditional density 仍為 normal
\[
p_{x(1)|y(0)}(x(1)|y(0)) = n(x(1), \hat x^-(1), P^-(1))
\]其中
\[\left\{ \begin{array}{l}
{{\hat x}^ - }\left( 1 \right) = A\hat x\left( 0 \right)\\
{P^ - }\left( 1 \right) = AP\left( 0 \right){A^T} + Q
\end{array} \right.\]接著我們僅需 遞迴重複上述步驟 $k=2,3,4,...$ 即可。以下我們給出總結:
Summary
定義 量測輸出從初始 直到 時間 $k$ 則
\[
{\bf y}(k) := \{y(0),y(1),...,y(k)\}
\]在 時間 $k$ 時,conditional density with data ${\bf y}(k-1)$ 為 normal
\[
p_{x(k)| {\bf y}(k-1)}(x(k) | {\bf y}(k-1)) = n(x(k), \hat x^-(k), P^-(k))
\]上述 mean 與 covariance matrix 有上標 $^-$ 號表示此估計為僅僅透過 量測 ${\bf y}(k-1)$ 的輸出,並未獲得 $k$ 時刻的量測輸出。 (表示用過去 $k-1$ 資料 預測 $k$ 的狀態! ) 注意到在 $k=0$,遞迴起始於 $\hat x^- (0) = \bar x(0)$ 與 $P^-(0) = Q(0)$。
接著我們會獲得 $y(k)$ 滿足
\[\left[ {\begin{array}{*{20}{c}}
{x\left( k \right)}\\
{y\left( k \right)}
\end{array}} \right] = \left[ {\begin{array}{*{20}{c}}
I&0\\
C&I
\end{array}} \right]\left[ {\begin{array}{*{20}{c}}
{x\left( k \right)}\\
{v\left( k \right)}
\end{array}} \right]
\]上式表示線性轉換。由於 量測雜訊 $v(k)$ 與 $x(k)$ 以及 ${\bf y}(k-1)$ 彼此獨立,故我們有 density of $(x(k), v(k))$
\[\underbrace {\left[ {\begin{array}{*{20}{c}}
{x\left( k \right)}\\
{v\left( k \right)}
\end{array}} \right]}_{ = \left( {\left[ {\begin{array}{*{20}{c}}
{x\left( k \right)}\\
{v\left( k \right)}
\end{array}} \right]|{\bf{y}}\left( {k - 1} \right)} \right)}\sim N\left( {\left[ {\begin{array}{*{20}{c}}
{{{\hat x}^ - }\left( k \right)}\\
0
\end{array}} \right],\left[ {\begin{array}{*{20}{c}}
{{P^ - }\left( k \right)}&0\\
0&R
\end{array}} \right]} \right)\]透過線性轉換結果,可得
\[\begin{array}{l}
\left[ {\begin{array}{*{20}{c}}
{x\left( k \right)}\\
{y\left( k \right)}
\end{array}} \right]\sim N\left( {\left[ {\begin{array}{*{20}{c}}
I&0\\
C&I
\end{array}} \right]\left[ {\begin{array}{*{20}{c}}
{{{\hat x}^ - }\left( k \right)}\\
0
\end{array}} \right],\left[ {\begin{array}{*{20}{c}}
I&0\\
C&I
\end{array}} \right]\left[ {\begin{array}{*{20}{c}}
{{P^ - }\left( k \right)}&0\\
0&R
\end{array}} \right]{{\left[ {\begin{array}{*{20}{c}}
I&0\\
C&I
\end{array}} \right]}^T}} \right)\\
\Rightarrow \left[ {\begin{array}{*{20}{c}}
{x\left( k \right)}\\
{y\left( k \right)}
\end{array}} \right]\sim N\left( {\left[ {\begin{array}{*{20}{c}}
{{{\hat x}^ - }\left( k \right)}\\
{C{{\hat x}^ - }\left( k \right)}
\end{array}} \right],\left[ {\begin{array}{*{20}{c}}
{{P^ - }\left( k \right)}&{{P^ - }\left( k \right){C^T}}\\
{C{P^ - }\left( k \right)}&{C{P^ - }\left( k \right){C^T} + R}
\end{array}} \right]} \right)
\end{array}\]注意到 $\{{\bf y}(k-1), y(k)\} \equiv {\bf y}(k)$ 故利用 conditional density 結果可得
\[
p_{x(k)|{\bf y} (k)}(x(k)| {\bf y}(k)) = n(x(k), \hat x(k), P(k))
\]其中
\[\left\{ {\begin{array}{*{20}{l}}
\begin{array}{l}
\hat x\left( k \right) = {{\hat x}^ - }\left( k \right) + L\left( k \right)(y\left( k \right) - C{{\hat x}^ - }\left( k \right))\\
L\left( k \right) = {P^ - }\left( k \right){C^T}\left( {C{P^ - }\left( k \right){C^T} + R} \right)_{}^{ - 1}
\end{array}\\
{P\left( k \right) = {P^ - }\left( k \right) - {P^ - }\left( k \right){C^T}\left( {C{P^ - }\left( k \right){C^T} + R} \right)_{}^{ - 1}C{P^ - }\left( k \right)}
\end{array}} \right.\]現在我們用下列模型來預估 基於 $k$ 時刻量測值 預估 $k+1$ 時刻
\[x\left( {k + 1} \right) = \left[ {\begin{array}{*{20}{c}}
A&I
\end{array}} \right]\left[ {\begin{array}{*{20}{c}}
{x\left( k \right)}\\
{w\left( k \right)}
\end{array}} \right]\]由於 $w(k)$ 與 $x(k)$ 以及 $\bf y$$(k)$ 彼此獨立,故 joint density of $(x(k),w(k))$ 可寫為
\[\left[ {\begin{array}{*{20}{c}}
{x\left( k \right)}\\
{w\left( k \right)}
\end{array}} \right]\sim N\left( {\left[ {\begin{array}{*{20}{c}}
{\hat x\left( k \right)}\\
0
\end{array}} \right],\left[ {\begin{array}{*{20}{c}}
{P\left( k \right)}&0\\
0&Q
\end{array}} \right]} \right)\]故 conditional density 為
\[{p_{x\left( {k + 1} \right)|{\bf{y}}\left( k \right)}}\left( {x\left( {k + 1} \right)|{\bf{y}}\left( k \right)} \right) = n\left( {x\left( {k + 1} \right),{{\hat x}^ - }\left( {k + 1} \right),{P^ - }\left( {k + 1} \right)} \right)\]其中
\[\left\{ \begin{array}{l}
{{\hat x}^ - }\left( {k + 1} \right) = A\hat x\left( k \right)\\
{P^ - }\left( {k + 1} \right) = AP\left( k \right){A^T} + Q
\end{array} \right.\]
2/07/2015
[最佳控制] 線性系統的最佳參數估計 Kalman Filter (0)- 預備知識
這次要介紹 Kalman filter 或稱 Optimal Linear State Estmator,以下我們將簡單介紹一些在下一篇文章需要使用的一些結果。
Preliminary
回憶若 $x$ 為 mean $m$ 且 variance $\sigma^2$ 的 Normal 隨機變數 則 我們表示為 $x \sim N(m, \sigma^2)$ 。其 probability density function 可記做
\[
\frac{1}{\sqrt{2 \pi} \sigma} \exp(\frac{-1}{2 \sigma^2}(x-m)^2)
\]現在若我們拓展上述結果到 多個隨機變數 (又稱 random vector 隨機向量) 的情況,令 $x$ 為Normal 隨機向量 記做
\[
x \sim N(m,P); \;\;
p_x(x) := n(x,m,P)
\]上述符號 表示 $x$ 為 normal distributed 且 mean vector $m$ 與 convariance matrix $P$。另外 $n(x,m,P)$ 表示 normal probability density function
\[\;n\left( {x,m,P} \right): = \frac{1}{{{{\left( {2\pi } \right)}^{n/2}}{{\left( {\det P} \right)}^{1/2}}}}\exp \left( { - \frac{1}{2}{{\left( {x - m} \right)}^T}{P^{ - 1}}\left( {x - m} \right)} \right)\]
Comment:
若 $x \in \mathbb{R}^n$ 則 mean vector $m \in \mathbb{R}^n$ 且 convariance matrix $P \in \mathbb{R}^{n \times n}$ 且為 實數 對稱 正定 矩陣 (正定條件用以確保 $P^{-1}$ 存在,使得上述的 probability density function 可以被定義)。若 $P$ 不為對 正定 我們稱為 singular normal distribution 或稱 degenerate normal。
Example
若 $n=2$ 則我們可以繪製 normal density function; 比如說
\[m = \left[ {\begin{array}{*{20}{c}}
0\\
0
\end{array}} \right];\begin{array}{*{20}{c}}
{}&{}
\end{array}{P^{ - 1}} = \left[ {\begin{array}{*{20}{c}}
{3.5}&{2.5}\\
{2.5}&{4.0}
\end{array}} \right]\]則我們可繪製
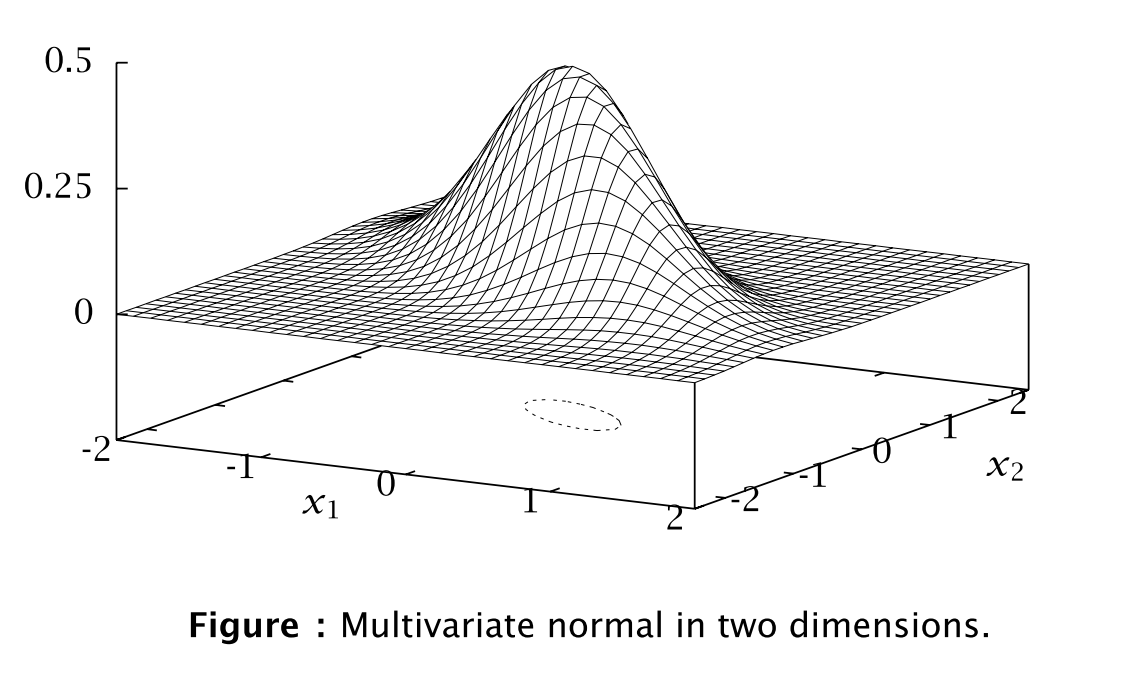
現在我們看幾個 之後會使用到的基本結果:
================
FACT 1: Joint independent normals
若隨機向量 $x \sim N(m_x,P_x)$ 與 $y \sim N(m_y,P_y)$ 為 normally distributed 且 彼此互為獨立,則其 joint density $p_{x,y}(x,y)$ 如下
\[
p_{x,y}(x,y) = p_{x}(x)p_{y}(y)=n(x,m_x,P_x) \cdot n(y,m_y,P_y)
\]且
\[\left[ {\begin{array}{*{20}{c}}
x\\
y
\end{array}} \right] \sim N\left( {\left[ {\begin{array}{*{20}{c}}
{{m_x}}\\
{{m_y}}
\end{array}} \right],\left[ {\begin{array}{*{20}{c}}
{{P_x}}&0\\
0&{{P_y}}
\end{array}} \right]} \right)\]================
================
FACT 2: Linear Transformation of a normal
若 $x \sim N(m, P)$ 且 $y$ 為 $x$ 的線性轉換;亦即對任意矩陣 $A$, $y = Ax$ 則
\[
y \sim N(Am , APA^T)
\]================
================
FACT 3: Conditional of a joint normal
若 $x,y$ 為 jointly normal distributed (no independent assumption)
\[\left[ {\begin{array}{*{20}{c}}
x\\
y
\end{array}} \right]\sim N\left( {\left[ {\begin{array}{*{20}{c}}
{{m_x}}\\
{{m_y}}
\end{array}} \right],\left[ {\begin{array}{*{20}{c}}
{{P_x}}&{{P_{xy}}}\\
{{P_{yx}}}&{{P_y}}
\end{array}} \right]} \right)\]則 conditional density of $x$ given $y$ 仍為 Normal 亦即
\[
(x|y) \sim N(m,P)
\]其 probability density function 為 $ p_{x|y} (x|y) = n(x,m,P)$ 其中 conditional mean vector $m$ 與 conditional convariance matrix $P$ 分別為
\[\begin{array}{l}
m = {m_x} + {P_{xy}}P_y^{ - 1}(y - {m_y})\\
P = {P_x} - {P_{xy}}P_y^{ - 1}{P_{yx}}
\end{array}\]================
注意到上式中 conditional mean $m$ 為 random vector (depends on $y$) 。
Proof:
回憶 conditional density of $x$ given y 定義
\[
p_{x|y}(x,y) := \frac{p_{x,y}(x,y)}{p_y(y)}
\]注意到 $(x,y)$ 為 joint normal 故我們有
\[\small \begin{array}{l}
{p_y}\left( y \right): = \frac{1}{{{{\left( {2\pi } \right)}^{{n_y}/2}}{{\left( {\det {P_y}} \right)}^{1/2}}}}\exp \left( { - \frac{1}{2}{{\left( {y - {m_y}} \right)}^T}{P_y}^{ - 1}\left( {y - {m_y}} \right)} \right)\\
{p_{x,y}}\left( {x,y} \right): = \frac{1}{{{{\left( {2\pi } \right)}^{\left( {{n_x} + {n_y}} \right)/2}}{{\left( {\det \left[ {\begin{array}{*{20}{c}}
{{P_x}}&{{P_{xy}}}\\
{{P_{yx}}}&{{P_y}}
\end{array}} \right]} \right)}^{1/2}}}}\exp \left( { - \frac{1}{2}{{\left[ {\begin{array}{*{20}{c}}
{x - {m_x}}\\
{y - {m_y}}
\end{array}} \right]}^T}{{\left[ {\begin{array}{*{20}{c}}
{{P_x}}&{{P_{xy}}}\\
{{P_{yx}}}&{{P_y}}
\end{array}} \right]}^{ - 1}}\left[ {\begin{array}{*{20}{c}}
{x - {m_x}}\\
{y - {m_y}}
\end{array}} \right]} \right)
\end{array}\]亦即
\[\begin{array}{l}
{p_{x|y}}\left( {x|y} \right) = \frac{{{p_{x,y}}\left( {x,y} \right)}}{{{p_y}\left( y \right)}}\\
\begin{array}{*{20}{c}}
{}&{}&{}&{}
\end{array} = \frac{{\frac{1}{{{{\left( {2\pi } \right)}^{\left( {{n_x} + {n_y}} \right)/2}}{{\left( {\det \left[ {\begin{array}{*{20}{c}}
{{P_x}}&{{P_{xy}}}\\
{{P_{yx}}}&{{P_y}}
\end{array}} \right]} \right)}^{1/2}}}}\exp \left( { - \frac{1}{2}{{\left[ {\begin{array}{*{20}{c}}
{x - {m_x}}\\
{y - {m_y}}
\end{array}} \right]}^T}{{\left[ {\begin{array}{*{20}{c}}
{{P_x}}&{{P_{xy}}}\\
{{P_{yx}}}&{{P_y}}
\end{array}} \right]}^{ - 1}}\left[ {\begin{array}{*{20}{c}}
{x - {m_x}}\\
{y - {m_y}}
\end{array}} \right]} \right)}}{{\frac{1}{{{{\left( {2\pi } \right)}^{{n_y}/2}}{{\left( {\det {P_y}} \right)}^{1/2}}}}\exp \left( { - \frac{1}{2}{{\left( {y - {m_y}} \right)}^T}{P_y}^{ - 1}\left( {y - {m_y}} \right)} \right)}}\\
\begin{array}{*{20}{c}}
{}&{}&{}&{}
\end{array} = \frac{{{{\left( {\det {P_y}} \right)}^{1/2}}\exp \left( { - \frac{1}{2}\left( {{{\left[ {\begin{array}{*{20}{c}}
{x - {m_x}}\\
{y - {m_y}}
\end{array}} \right]}^T}{{\left[ {\begin{array}{*{20}{c}}
{{P_x}}&{{P_{xy}}}\\
{{P_{yx}}}&{{P_y}}
\end{array}} \right]}^{ - 1}}\left[ {\begin{array}{*{20}{c}}
{x - {m_x}}\\
{y - {m_y}}
\end{array}} \right] - {{\left( {y - {m_y}} \right)}^T}{P_y}^{ - 1}\left( {y - {m_y}} \right)} \right)} \right)}}{{{{\left( {2\pi } \right)}^{{n_x}/2}}{{\left( {\det \left[ {\begin{array}{*{20}{c}}
{{P_x}}&{{P_{xy}}}\\
{{P_{yx}}}&{{P_y}}
\end{array}} \right]} \right)}^{1/2}}}}
\end{array}\]注意到若我們取 $P:= P_x - P_{xy}P_y^{-1}P_{yx}$ 則 利用 Matrix inversion Lemma 可知
\[{\left[ {\begin{array}{*{20}{c}}
{{P_x}}&{{P_{xy}}}\\
{{P_{yx}}}&{{P_y}}
\end{array}} \right]^{ - 1}} = \left[ {\begin{array}{*{20}{c}}
{{P^{ - 1}}}&{ - {P^{ - 1}}{P_{xy}}P_y^{ - 1}}\\
{ - P_y^{ - 1}{P_{yx}}{P^{ - 1}}}&{P_y^{ - 1} + P_y^{ - 1}{P_{yx}}{P^{ - 1}}{P_{xy}}P_y^{ - 1}}
\end{array}} \right]\]將此結果帶回我們可得
\[\begin{array}{l}
{p_{x|y}}\left( {x|y} \right) = \frac{{{p_{x,y}}\left( {x,y} \right)}}{{{p_y}\left( y \right)}}\\
\begin{array}{*{20}{c}}
{}&{}&{}
\end{array} = \frac{{{{\left( {\det {P_y}} \right)}^{1/2}}\exp \left( { - \frac{1}{2}\left( \begin{array}{l}
{\left( {x - {m_x}} \right)^T}{P^{ - 1}}\left( {x - {m_x}} \right) - 2{\left( {y - {m_y}} \right)^T}P_y^{ - 1}{P_{yx}}{P^{ - 1}}\left( {x - {m_x}} \right)\\
\begin{array}{*{20}{c}}
{}&{}
\end{array} + {\left( {y - {m_y}} \right)^T}\left( {P_y^{ - 1}{P_{yx}}{P^{ - 1}}{P_{xy}}P_y^{ - 1}} \right)\left( {y - {m_y}} \right)
\end{array} \right)} \right)}}{{{{\left( {2\pi } \right)}^{{n_x}/2}}{{\left( {\det \left[ {\begin{array}{*{20}{c}}
{{P_x}}&{{P_{xy}}}\\
{{P_{yx}}}&{{P_y}}
\end{array}} \right]} \right)}^{1/2}}}}\\
\begin{array}{*{20}{c}}
{}&{}&{}
\end{array} = \frac{{{{\left( {\det {P_y}} \right)}^{1/2}}\exp \left( { - \frac{1}{2}\left( {{{\left[ {{{\left( {x - {m_x}} \right)}^T} - {P_{xy}}P_y^{ - 1}\left( {y - {m_y}} \right)} \right]}^T}{P^{ - 1}}\left[ {{{\left( {x - {m_x}} \right)}^T} - {P_{xy}}P_y^{ - 1}\left( {y - {m_y}} \right)} \right]} \right)} \right)}}{{{{\left( {2\pi } \right)}^{{n_x}/2}}{{\left( {\det \left[ {\begin{array}{*{20}{c}}
{{P_x}}&{{P_{xy}}}\\
{{P_{yx}}}&{{P_y}}
\end{array}} \right]} \right)}^{1/2}}}}\\
\begin{array}{*{20}{c}}
{}&{}&{}
\end{array} = \frac{{{{\left( {\det {P_y}} \right)}^{1/2}}\exp \left( { - \frac{1}{2}\left( {{{\left[ {\left( {x - {m_x}} \right) - {P_{xy}}P_y^{ - 1}\left( {y - {m_y}} \right)} \right]}^T}{P^{ - 1}}\left[ {\left( {x - {m_x}} \right) - {P_{xy}}P_y^{ - 1}\left( {y - {m_y}} \right)} \right]} \right)} \right)}}{{{{\left( {2\pi } \right)}^{{n_x}/2}}{{\left( {\det \left[ {\begin{array}{*{20}{c}}
{{P_x}}&{{P_{xy}}}\\
{{P_{yx}}}&{{P_y}}
\end{array}} \right]} \right)}^{1/2}}}}
\end{array}\]接著令 $m := m_x + P_{xy} P_y^{-1}(y-m_y)$ 可得
\[{p_{x|y}}\left( {x|y} \right) = \frac{{{p_{x,y}}\left( {x,y} \right)}}{{{p_y}\left( y \right)}} = \frac{{{{\left( {\det {P_y}} \right)}^{1/2}}\exp \left( { - \frac{1}{2}{{\left( {x - m} \right)}^T}{P^{ - 1}}\left( {x - m} \right)} \right)}}{{{{\left( {2\pi } \right)}^{{n_x}/2}}{{\left( {\det \left[ {\begin{array}{*{20}{c}}
{{P_x}}&{{P_{xy}}}\\
{{P_{yx}}}&{{P_y}}
\end{array}} \right]} \right)}^{1/2}}}}\]注意到
\[\det \left[ {\begin{array}{*{20}{c}}
{{P_x}}&{{P_{xy}}}\\
{{P_{yx}}}&{{P_y}}
\end{array}} \right] = \det {P_y}\det P\]故可得
\[{p_{x|y}}\left( {x|y} \right) = \frac{1}{{{{\left( {2\pi } \right)}^{{n_x}/2}}{{\left( {\det P} \right)}^{1/2}}}}\exp \left( { - \frac{1}{2}{{\left( {x - m} \right)}^T}{P^{ - 1}}\left( {x - m} \right)} \right) = n(x,m,P) \ \ \ \ \ \square
\]
如果要推導 最佳估測器 我們需要上述結果衍生:
================
FACT 1': Joint independent normals
若 $p_{x|z} (x|z) = n(x, m_x, P_x)$ 為 normal ,令 $y \sim N(m_y, P_y)$ 且 與 $x,z$ 彼此獨立 則 conditional joint density of $(x,y)$ given $z$ 為
\[{p_{x,y|z}}\left( {\left[ {\begin{array}{*{20}{c}}
x\\
y
\end{array}} \right]|z} \right) = n\left( {\left[ {\begin{array}{*{20}{c}}
x\\
y
\end{array}} \right],\left[ {\begin{array}{*{20}{c}}
{{m_x}}\\
{{m_y}}
\end{array}} \right],\left[ {\begin{array}{*{20}{c}}
{{P_x}}&0\\
0&{{P_y}}
\end{array}} \right]} \right)\]================
================
FACT 2': Linear Transformation of a Normal
若 $p_{x|z}(x|z)= n(x,m, P)$ 且 $y$ 為 $x$ 的線性轉換;亦即 $y = Ax$ 則
\[{p_{y|z}}(y|z) = n(y,Am,AP{A^T})\]================
================
Preliminary
回憶若 $x$ 為 mean $m$ 且 variance $\sigma^2$ 的 Normal 隨機變數 則 我們表示為 $x \sim N(m, \sigma^2)$ 。其 probability density function 可記做
\[
\frac{1}{\sqrt{2 \pi} \sigma} \exp(\frac{-1}{2 \sigma^2}(x-m)^2)
\]現在若我們拓展上述結果到 多個隨機變數 (又稱 random vector 隨機向量) 的情況,令 $x$ 為Normal 隨機向量 記做
\[
x \sim N(m,P); \;\;
p_x(x) := n(x,m,P)
\]上述符號 表示 $x$ 為 normal distributed 且 mean vector $m$ 與 convariance matrix $P$。另外 $n(x,m,P)$ 表示 normal probability density function
\[\;n\left( {x,m,P} \right): = \frac{1}{{{{\left( {2\pi } \right)}^{n/2}}{{\left( {\det P} \right)}^{1/2}}}}\exp \left( { - \frac{1}{2}{{\left( {x - m} \right)}^T}{P^{ - 1}}\left( {x - m} \right)} \right)\]
Comment:
若 $x \in \mathbb{R}^n$ 則 mean vector $m \in \mathbb{R}^n$ 且 convariance matrix $P \in \mathbb{R}^{n \times n}$ 且為 實數 對稱 正定 矩陣 (正定條件用以確保 $P^{-1}$ 存在,使得上述的 probability density function 可以被定義)。若 $P$ 不為對 正定 我們稱為 singular normal distribution 或稱 degenerate normal。
Example
若 $n=2$ 則我們可以繪製 normal density function; 比如說
\[m = \left[ {\begin{array}{*{20}{c}}
0\\
0
\end{array}} \right];\begin{array}{*{20}{c}}
{}&{}
\end{array}{P^{ - 1}} = \left[ {\begin{array}{*{20}{c}}
{3.5}&{2.5}\\
{2.5}&{4.0}
\end{array}} \right]\]則我們可繪製
現在我們看幾個 之後會使用到的基本結果:
================
FACT 1: Joint independent normals
若隨機向量 $x \sim N(m_x,P_x)$ 與 $y \sim N(m_y,P_y)$ 為 normally distributed 且 彼此互為獨立,則其 joint density $p_{x,y}(x,y)$ 如下
\[
p_{x,y}(x,y) = p_{x}(x)p_{y}(y)=n(x,m_x,P_x) \cdot n(y,m_y,P_y)
\]且
\[\left[ {\begin{array}{*{20}{c}}
x\\
y
\end{array}} \right] \sim N\left( {\left[ {\begin{array}{*{20}{c}}
{{m_x}}\\
{{m_y}}
\end{array}} \right],\left[ {\begin{array}{*{20}{c}}
{{P_x}}&0\\
0&{{P_y}}
\end{array}} \right]} \right)\]================
================
FACT 2: Linear Transformation of a normal
若 $x \sim N(m, P)$ 且 $y$ 為 $x$ 的線性轉換;亦即對任意矩陣 $A$, $y = Ax$ 則
\[
y \sim N(Am , APA^T)
\]================
================
FACT 3: Conditional of a joint normal
若 $x,y$ 為 jointly normal distributed (no independent assumption)
\[\left[ {\begin{array}{*{20}{c}}
x\\
y
\end{array}} \right]\sim N\left( {\left[ {\begin{array}{*{20}{c}}
{{m_x}}\\
{{m_y}}
\end{array}} \right],\left[ {\begin{array}{*{20}{c}}
{{P_x}}&{{P_{xy}}}\\
{{P_{yx}}}&{{P_y}}
\end{array}} \right]} \right)\]則 conditional density of $x$ given $y$ 仍為 Normal 亦即
\[
(x|y) \sim N(m,P)
\]其 probability density function 為 $ p_{x|y} (x|y) = n(x,m,P)$ 其中 conditional mean vector $m$ 與 conditional convariance matrix $P$ 分別為
\[\begin{array}{l}
m = {m_x} + {P_{xy}}P_y^{ - 1}(y - {m_y})\\
P = {P_x} - {P_{xy}}P_y^{ - 1}{P_{yx}}
\end{array}\]================
注意到上式中 conditional mean $m$ 為 random vector (depends on $y$) 。
Proof:
回憶 conditional density of $x$ given y 定義
\[
p_{x|y}(x,y) := \frac{p_{x,y}(x,y)}{p_y(y)}
\]注意到 $(x,y)$ 為 joint normal 故我們有
\[\small \begin{array}{l}
{p_y}\left( y \right): = \frac{1}{{{{\left( {2\pi } \right)}^{{n_y}/2}}{{\left( {\det {P_y}} \right)}^{1/2}}}}\exp \left( { - \frac{1}{2}{{\left( {y - {m_y}} \right)}^T}{P_y}^{ - 1}\left( {y - {m_y}} \right)} \right)\\
{p_{x,y}}\left( {x,y} \right): = \frac{1}{{{{\left( {2\pi } \right)}^{\left( {{n_x} + {n_y}} \right)/2}}{{\left( {\det \left[ {\begin{array}{*{20}{c}}
{{P_x}}&{{P_{xy}}}\\
{{P_{yx}}}&{{P_y}}
\end{array}} \right]} \right)}^{1/2}}}}\exp \left( { - \frac{1}{2}{{\left[ {\begin{array}{*{20}{c}}
{x - {m_x}}\\
{y - {m_y}}
\end{array}} \right]}^T}{{\left[ {\begin{array}{*{20}{c}}
{{P_x}}&{{P_{xy}}}\\
{{P_{yx}}}&{{P_y}}
\end{array}} \right]}^{ - 1}}\left[ {\begin{array}{*{20}{c}}
{x - {m_x}}\\
{y - {m_y}}
\end{array}} \right]} \right)
\end{array}\]亦即
\[\begin{array}{l}
{p_{x|y}}\left( {x|y} \right) = \frac{{{p_{x,y}}\left( {x,y} \right)}}{{{p_y}\left( y \right)}}\\
\begin{array}{*{20}{c}}
{}&{}&{}&{}
\end{array} = \frac{{\frac{1}{{{{\left( {2\pi } \right)}^{\left( {{n_x} + {n_y}} \right)/2}}{{\left( {\det \left[ {\begin{array}{*{20}{c}}
{{P_x}}&{{P_{xy}}}\\
{{P_{yx}}}&{{P_y}}
\end{array}} \right]} \right)}^{1/2}}}}\exp \left( { - \frac{1}{2}{{\left[ {\begin{array}{*{20}{c}}
{x - {m_x}}\\
{y - {m_y}}
\end{array}} \right]}^T}{{\left[ {\begin{array}{*{20}{c}}
{{P_x}}&{{P_{xy}}}\\
{{P_{yx}}}&{{P_y}}
\end{array}} \right]}^{ - 1}}\left[ {\begin{array}{*{20}{c}}
{x - {m_x}}\\
{y - {m_y}}
\end{array}} \right]} \right)}}{{\frac{1}{{{{\left( {2\pi } \right)}^{{n_y}/2}}{{\left( {\det {P_y}} \right)}^{1/2}}}}\exp \left( { - \frac{1}{2}{{\left( {y - {m_y}} \right)}^T}{P_y}^{ - 1}\left( {y - {m_y}} \right)} \right)}}\\
\begin{array}{*{20}{c}}
{}&{}&{}&{}
\end{array} = \frac{{{{\left( {\det {P_y}} \right)}^{1/2}}\exp \left( { - \frac{1}{2}\left( {{{\left[ {\begin{array}{*{20}{c}}
{x - {m_x}}\\
{y - {m_y}}
\end{array}} \right]}^T}{{\left[ {\begin{array}{*{20}{c}}
{{P_x}}&{{P_{xy}}}\\
{{P_{yx}}}&{{P_y}}
\end{array}} \right]}^{ - 1}}\left[ {\begin{array}{*{20}{c}}
{x - {m_x}}\\
{y - {m_y}}
\end{array}} \right] - {{\left( {y - {m_y}} \right)}^T}{P_y}^{ - 1}\left( {y - {m_y}} \right)} \right)} \right)}}{{{{\left( {2\pi } \right)}^{{n_x}/2}}{{\left( {\det \left[ {\begin{array}{*{20}{c}}
{{P_x}}&{{P_{xy}}}\\
{{P_{yx}}}&{{P_y}}
\end{array}} \right]} \right)}^{1/2}}}}
\end{array}\]注意到若我們取 $P:= P_x - P_{xy}P_y^{-1}P_{yx}$ 則 利用 Matrix inversion Lemma 可知
\[{\left[ {\begin{array}{*{20}{c}}
{{P_x}}&{{P_{xy}}}\\
{{P_{yx}}}&{{P_y}}
\end{array}} \right]^{ - 1}} = \left[ {\begin{array}{*{20}{c}}
{{P^{ - 1}}}&{ - {P^{ - 1}}{P_{xy}}P_y^{ - 1}}\\
{ - P_y^{ - 1}{P_{yx}}{P^{ - 1}}}&{P_y^{ - 1} + P_y^{ - 1}{P_{yx}}{P^{ - 1}}{P_{xy}}P_y^{ - 1}}
\end{array}} \right]\]將此結果帶回我們可得
\[\begin{array}{l}
{p_{x|y}}\left( {x|y} \right) = \frac{{{p_{x,y}}\left( {x,y} \right)}}{{{p_y}\left( y \right)}}\\
\begin{array}{*{20}{c}}
{}&{}&{}
\end{array} = \frac{{{{\left( {\det {P_y}} \right)}^{1/2}}\exp \left( { - \frac{1}{2}\left( \begin{array}{l}
{\left( {x - {m_x}} \right)^T}{P^{ - 1}}\left( {x - {m_x}} \right) - 2{\left( {y - {m_y}} \right)^T}P_y^{ - 1}{P_{yx}}{P^{ - 1}}\left( {x - {m_x}} \right)\\
\begin{array}{*{20}{c}}
{}&{}
\end{array} + {\left( {y - {m_y}} \right)^T}\left( {P_y^{ - 1}{P_{yx}}{P^{ - 1}}{P_{xy}}P_y^{ - 1}} \right)\left( {y - {m_y}} \right)
\end{array} \right)} \right)}}{{{{\left( {2\pi } \right)}^{{n_x}/2}}{{\left( {\det \left[ {\begin{array}{*{20}{c}}
{{P_x}}&{{P_{xy}}}\\
{{P_{yx}}}&{{P_y}}
\end{array}} \right]} \right)}^{1/2}}}}\\
\begin{array}{*{20}{c}}
{}&{}&{}
\end{array} = \frac{{{{\left( {\det {P_y}} \right)}^{1/2}}\exp \left( { - \frac{1}{2}\left( {{{\left[ {{{\left( {x - {m_x}} \right)}^T} - {P_{xy}}P_y^{ - 1}\left( {y - {m_y}} \right)} \right]}^T}{P^{ - 1}}\left[ {{{\left( {x - {m_x}} \right)}^T} - {P_{xy}}P_y^{ - 1}\left( {y - {m_y}} \right)} \right]} \right)} \right)}}{{{{\left( {2\pi } \right)}^{{n_x}/2}}{{\left( {\det \left[ {\begin{array}{*{20}{c}}
{{P_x}}&{{P_{xy}}}\\
{{P_{yx}}}&{{P_y}}
\end{array}} \right]} \right)}^{1/2}}}}\\
\begin{array}{*{20}{c}}
{}&{}&{}
\end{array} = \frac{{{{\left( {\det {P_y}} \right)}^{1/2}}\exp \left( { - \frac{1}{2}\left( {{{\left[ {\left( {x - {m_x}} \right) - {P_{xy}}P_y^{ - 1}\left( {y - {m_y}} \right)} \right]}^T}{P^{ - 1}}\left[ {\left( {x - {m_x}} \right) - {P_{xy}}P_y^{ - 1}\left( {y - {m_y}} \right)} \right]} \right)} \right)}}{{{{\left( {2\pi } \right)}^{{n_x}/2}}{{\left( {\det \left[ {\begin{array}{*{20}{c}}
{{P_x}}&{{P_{xy}}}\\
{{P_{yx}}}&{{P_y}}
\end{array}} \right]} \right)}^{1/2}}}}
\end{array}\]接著令 $m := m_x + P_{xy} P_y^{-1}(y-m_y)$ 可得
\[{p_{x|y}}\left( {x|y} \right) = \frac{{{p_{x,y}}\left( {x,y} \right)}}{{{p_y}\left( y \right)}} = \frac{{{{\left( {\det {P_y}} \right)}^{1/2}}\exp \left( { - \frac{1}{2}{{\left( {x - m} \right)}^T}{P^{ - 1}}\left( {x - m} \right)} \right)}}{{{{\left( {2\pi } \right)}^{{n_x}/2}}{{\left( {\det \left[ {\begin{array}{*{20}{c}}
{{P_x}}&{{P_{xy}}}\\
{{P_{yx}}}&{{P_y}}
\end{array}} \right]} \right)}^{1/2}}}}\]注意到
\[\det \left[ {\begin{array}{*{20}{c}}
{{P_x}}&{{P_{xy}}}\\
{{P_{yx}}}&{{P_y}}
\end{array}} \right] = \det {P_y}\det P\]故可得
\[{p_{x|y}}\left( {x|y} \right) = \frac{1}{{{{\left( {2\pi } \right)}^{{n_x}/2}}{{\left( {\det P} \right)}^{1/2}}}}\exp \left( { - \frac{1}{2}{{\left( {x - m} \right)}^T}{P^{ - 1}}\left( {x - m} \right)} \right) = n(x,m,P) \ \ \ \ \ \square
\]
如果要推導 最佳估測器 我們需要上述結果衍生:
================
FACT 1': Joint independent normals
若 $p_{x|z} (x|z) = n(x, m_x, P_x)$ 為 normal ,令 $y \sim N(m_y, P_y)$ 且 與 $x,z$ 彼此獨立 則 conditional joint density of $(x,y)$ given $z$ 為
\[{p_{x,y|z}}\left( {\left[ {\begin{array}{*{20}{c}}
x\\
y
\end{array}} \right]|z} \right) = n\left( {\left[ {\begin{array}{*{20}{c}}
x\\
y
\end{array}} \right],\left[ {\begin{array}{*{20}{c}}
{{m_x}}\\
{{m_y}}
\end{array}} \right],\left[ {\begin{array}{*{20}{c}}
{{P_x}}&0\\
0&{{P_y}}
\end{array}} \right]} \right)\]================
================
FACT 2': Linear Transformation of a Normal
若 $p_{x|z}(x|z)= n(x,m, P)$ 且 $y$ 為 $x$ 的線性轉換;亦即 $y = Ax$ 則
\[{p_{y|z}}(y|z) = n(y,Am,AP{A^T})\]================
================
FACT 3': Conditional of a joint normal
若 $x,y$ 為 jointly normal distributed (no independent assumption)
\[{p_{x,y|z}}\left( {\left[ {\begin{array}{*{20}{c}}
x\\
y
\end{array}} \right]|z} \right) = n\left( {\left[ {\begin{array}{*{20}{c}}
x\\
y
\end{array}} \right],\left[ {\begin{array}{*{20}{c}}
{{m_x}}\\
{{m_y}}
\end{array}} \right],\left[ {\begin{array}{*{20}{c}}
{{P_x}}&{{P_{xy}}}\\
{{P_{yx}}}&{{P_y}}
\end{array}} \right]} \right)\]則 conditional density of $x$ given $y,z$ 仍為 Normal ,記為
\[
p_{x|y,z} (x|y,z) = n(x,m,P)
\]其中 conditional mean vector $m$ 與 conditional convariance matrix $P$ 分別為
\[\begin{array}{l}
m = {m_x} + {P_{xy}}P_y^{ - 1}(y - {m_y})\\
P = {P_x} - {P_{xy}}P_y^{ - 1}{P_{yx}}
\end{array}\]
================
Proof:
由 conditional density of $x$ given $y,z$ 定義可知
\[{p_{x|y,z}}\left( {x|y,z} \right) = \frac{{{p_{x,y,z}}\left( {x,y,z} \right)}}{{{p_{y,z}}\left( {y,z} \right)}}\]現在對等號右方 分子分母同乘 $p(z)$ 可得
\[\begin{array}{l} {p_{x|y,z}}\left( {x|y,z} \right) = \frac{{{p_{x,y,z}}\left( {x,y,z} \right)}}{{{p_{y,z}}\left( {y,z} \right)}}\\ \begin{array}{*{20}{c}} {}&{}&{} \end{array} = \frac{{{p_{x,y,z}}\left( {x,y,z} \right)}}{{{p_z}\left( z \right)}}\frac{{{p_z}\left( z \right)}}{{{p_{y,z}}\left( {y,z} \right)}}\\ \begin{array}{*{20}{c}} {}&{}&{} \end{array} = {p_{x,y|z}}\left( {x,y|z} \right) \cdot \frac{1}{{{p_{y|z}}\left( {y|z} \right)}} \end{array}\]則由先前 FACT 3 可計算 $p(y,z)$ 並且帶入 $p(x,y|z)$ 即可求得所求。$\square$
ref: J. B. Rawlings and D. Q. Mayne, "Model Predictive Control: Theory and Design".
若 $x,y$ 為 jointly normal distributed (no independent assumption)
\[{p_{x,y|z}}\left( {\left[ {\begin{array}{*{20}{c}}
x\\
y
\end{array}} \right]|z} \right) = n\left( {\left[ {\begin{array}{*{20}{c}}
x\\
y
\end{array}} \right],\left[ {\begin{array}{*{20}{c}}
{{m_x}}\\
{{m_y}}
\end{array}} \right],\left[ {\begin{array}{*{20}{c}}
{{P_x}}&{{P_{xy}}}\\
{{P_{yx}}}&{{P_y}}
\end{array}} \right]} \right)\]則 conditional density of $x$ given $y,z$ 仍為 Normal ,記為
\[
p_{x|y,z} (x|y,z) = n(x,m,P)
\]其中 conditional mean vector $m$ 與 conditional convariance matrix $P$ 分別為
\[\begin{array}{l}
m = {m_x} + {P_{xy}}P_y^{ - 1}(y - {m_y})\\
P = {P_x} - {P_{xy}}P_y^{ - 1}{P_{yx}}
\end{array}\]
================
Proof:
由 conditional density of $x$ given $y,z$ 定義可知
\[{p_{x|y,z}}\left( {x|y,z} \right) = \frac{{{p_{x,y,z}}\left( {x,y,z} \right)}}{{{p_{y,z}}\left( {y,z} \right)}}\]現在對等號右方 分子分母同乘 $p(z)$ 可得
\[\begin{array}{l} {p_{x|y,z}}\left( {x|y,z} \right) = \frac{{{p_{x,y,z}}\left( {x,y,z} \right)}}{{{p_{y,z}}\left( {y,z} \right)}}\\ \begin{array}{*{20}{c}} {}&{}&{} \end{array} = \frac{{{p_{x,y,z}}\left( {x,y,z} \right)}}{{{p_z}\left( z \right)}}\frac{{{p_z}\left( z \right)}}{{{p_{y,z}}\left( {y,z} \right)}}\\ \begin{array}{*{20}{c}} {}&{}&{} \end{array} = {p_{x,y|z}}\left( {x,y|z} \right) \cdot \frac{1}{{{p_{y|z}}\left( {y|z} \right)}} \end{array}\]則由先前 FACT 3 可計算 $p(y,z)$ 並且帶入 $p(x,y|z)$ 即可求得所求。$\square$
ref: J. B. Rawlings and D. Q. Mayne, "Model Predictive Control: Theory and Design".
訂閱:
文章 (Atom)
-
這次要介紹的是數學上一個重要的概念: Norm: 一般翻譯成 範數 (在英語中 norm 有規範的意思,比如我們說normalization就是把某種東西/物品/事件 做 正規化,也就是加上規範使其正常化),不過個人認為其實翻譯成 範數 也是看不懂的...這邊建議把 No...
-
數學上的 if and only if ( 此文不討論邏輯學中的 if and only if,只討論數學上的 if and only if。) 中文翻譯叫做 若且唯若 (or 當且僅當) , 記得當初剛接觸這個詞彙的時候,我是完全不明白到底是甚麼意思,查了翻譯也是愛...
-
 半導體中的電流是由電子(electron)及電洞(hole)兩種載子(carrier)移動所產生 載子移動的方式: 擴散(diffusion) $\Rightarrow$ 擴散電流 (不受外力電場作用) 飄移(drift) $\Rightarrow$ 飄移電流 (受外...
半導體中的電流是由電子(electron)及電洞(hole)兩種載子(carrier)移動所產生 載子移動的方式: 擴散(diffusion) $\Rightarrow$ 擴散電流 (不受外力電場作用) 飄移(drift) $\Rightarrow$ 飄移電流 (受外...